Getting Started#
This notebook gets you started with a brief nDCG evaluation with LensKit for Python.
This notebook is also available on Google Collaboratory and nbviewer.
Setup#
We first import the LensKit components we need:
from lenskit.als import BiasedMFScorer
from lenskit.batch import recommend
from lenskit.data import ItemListCollection, UserIDKey, load_movielens
from lenskit.knn import ItemKNNScorer
from lenskit.metrics import NDCG, RBP, MeasurementCollector, RecipRank
from lenskit.pipeline import topn_pipeline
from lenskit.splitting import SampleFrac, crossfold_users
And Pandas is very useful, as is Seaborn for plotting:
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
The pyprojroot package makes it easy to find input data:
from pyprojroot.here import here
Loading Data#
We’re going to use the ML-100K data set:
ml100k = load_movielens(here("data/ml-100k.zip"))
ml100k.interaction_table(format="pandas", original_ids=True).head()
/Users/mde48/LensKit/lkpy/src/lenskit/data/movielens.py:143: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support regex separators (separators > 1 char and different from '\s+' are interpreted as regex); you can avoid this warning by specifying engine='python'.
return pd.read_csv(
/Users/mde48/LensKit/lkpy/src/lenskit/data/movielens.py:157: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support regex separators (separators > 1 char and different from '\s+' are interpreted as regex); you can avoid this warning by specifying engine='python'.
return pd.read_csv(
| user_id | item_id | rating | timestamp | |
|---|---|---|---|---|
| 0 | 1 | 1 | 5.0 | 1997-09-22 22:02:38 |
| 1 | 1 | 2 | 3.0 | 1997-10-15 05:26:11 |
| 2 | 1 | 3 | 4.0 | 1997-11-03 07:42:40 |
| 3 | 1 | 4 | 3.0 | 1997-10-15 05:25:19 |
| 4 | 1 | 5 | 3.0 | 1998-03-13 01:15:12 |
Defining Recommenders#
Let’s set up two scoring models:
model_ii = ItemKNNScorer(k=20)
model_als = BiasedMFScorer(features=50)
For each of these, we also need to make a :ref:pipeline <pipeline>:
pipe_ii = topn_pipeline(model_ii)
pipe_als = topn_pipeline(model_als)
Running the Evaluation#
In LensKit, our evaluation proceeds in 2 steps:
Generate recommendations
Measure them
If memory is a concern, we can measure while generating, but we will not do that for now.
Let’s start by creating and collecting the recommendations; we will generate 100 recommendations per user, and will collect all of them into a single ItemListCollection:
# test data is organized by user
all_test = ItemListCollection(UserIDKey)
# recommendations will be organized by model and user ID
# create a new empty list for each recommender
als_recs = ItemListCollection(UserIDKey)
iknn_recs = ItemListCollection(UserIDKey)
for split in crossfold_users(ml100k, 5, SampleFrac(0.2)):
# collect the test data
all_test.add_from(split.test)
# train the pipeline, cloning first so a fresh pipeline for each split
fit_als = pipe_als.clone()
fit_als.train(split.train)
# generate recs
recs = recommend(fit_als, split.test.keys(), 100)
als_recs.add_from(recs)
# do the same for item-item
fit_ii = pipe_ii.clone()
fit_ii.train(split.train)
recs = recommend(fit_ii, split.test.keys(), 100)
iknn_recs.add_from(recs)
Measuring Recommendations#
We analyze our recommendation lists with a RunAnalysis and some metrics.
First we set up a collector:
mc = MeasurementCollector()
mc.add_metric(NDCG(n=100))
mc.add_metric(RBP(n=100))
mc.add_metric(RecipRank(n=100))
Then we measure each of the recommendation sets:
als_summary, als_metrics = mc.measure_run(als_recs, all_test)
iknn_summary, iknn_metrics = mc.measure_run(iknn_recs, all_test)
Now we have nDCG values, along with some other metrics! We can combine them and start computing and plotting.
list_metrics = pd.concat(
{
"ALS": als_metrics,
"IKNN": iknn_metrics,
},
names=["model"],
)
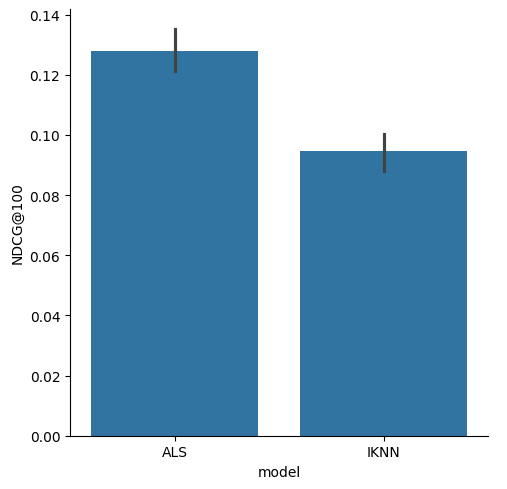
list_metrics.groupby("model").mean()
| NDCG@100 | RBP@100 | RecipRank@100 | |
|---|---|---|---|
| model | |||
| ALS | 0.128064 | 0.083101 | 0.213430 |
| IKNN | 0.094535 | 0.044154 | 0.110067 |
sns.catplot(list_metrics.reset_index(), x="model", y="NDCG@100", kind="bar")
plt.show()